Java Map
HashMap 的底层数据结构
JDK 8 中 HashMap 的数据结构是数组+链表+红黑树
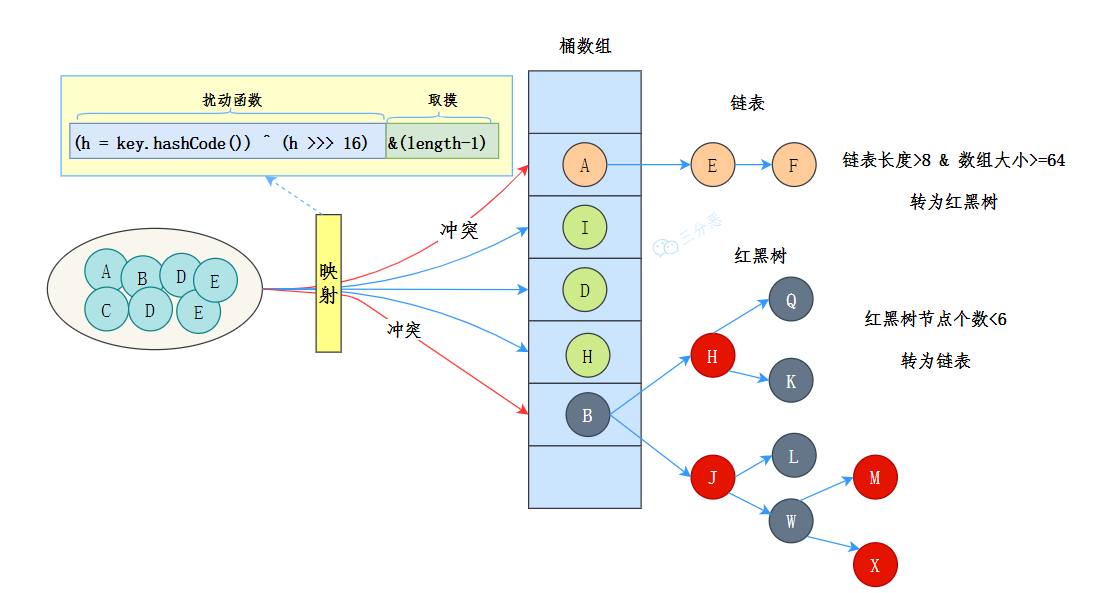
数组用来存储键值对,每个键值对可以通过索引直接拿到,索引是通过对键的哈希值进行进一步的 hash() 处理得到的。
当多个键经过哈希处理后得到相同的索引时,需要通过链表来解决哈希冲突——将具有相同索引的键值对通过链表存储起来。
不过,链表过长时,查询效率会比较低,于是当链表的长度超过 8 时(且数组的长度大于 64),链表就会转换为红黑树。红黑树的查询效率是 O(logn),比链表的 O(n) 要快。
hash() 方法的目标是尽量减少哈希冲突,保证元素能够均匀地分布在数组的每个位置上。
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}如果键的哈希值已经在数组中存在,其对应的值将被新值覆盖。
HashMap 的初始容量是 16,随着元素的不断添加,HashMap 就需要进行扩容,阈值是capacity * loadFactor,capacity 为容量,loadFactor 为负载因子,默认为 0.75。
扩容后的数组大小是原来的 2 倍,然后把原来的元素重新计算哈希值,放到新的数组中
哈希取值平均时间复杂度 O (1) 是怎么来的
哈希表的本质是用一段连续的数组空间来存储数据,并通过一个 哈希函数(Hash Function) 将键(Key)直接映射为数组的下标(索引)
在最完美的理想状态下:每个不同的 Key 都能被计算成不同的数组下标,并且不存在两个不同的 Key 算出同一个下标
在这种情况下,插入、删除、查找都只需要计算 hash(key) 得到下标,然后直接访问该下标位置的内存
但是现实中,冲突不可能被避免,必然存在两个不同的 Key 算出了相同的哈希值
为了处理冲突,数组不再直接存值,而是存一个 链表(或红黑树) 的头指针。取值的步骤就变成了算哈希,找到数组下标。如果该槽位空,直接放;如果有值,把新元素挂在链表上。取值时,找到槽位后,遍历链表比对 Key
而对于平均复杂度,可以理解为随即找一个key,预期要比多少次才能找到
如果这个包含的内容少,那么比较次数肯定就是1
比如说数组长度为8,有8个元素,且不重复无hash冲突,那么取hash值后直接去相应数组下标取值即可
但当长度为10,有20个元素时,随机找一个 key,里面平均有2个元素
根据hash表性质,可以理解为每个数组都连接了一个长度为2的链表,接下来还得在链表上找对应的,:平均次数为二分之链表长度
依旧是常数,所以平均复杂度为O(1+二分之链表长度)=O()
HashMap 的 put 流程
哈希寻址 → 处理哈希冲突(链表还是红黑树)→ 判断是否需要扩容 → 插入/覆盖节点。
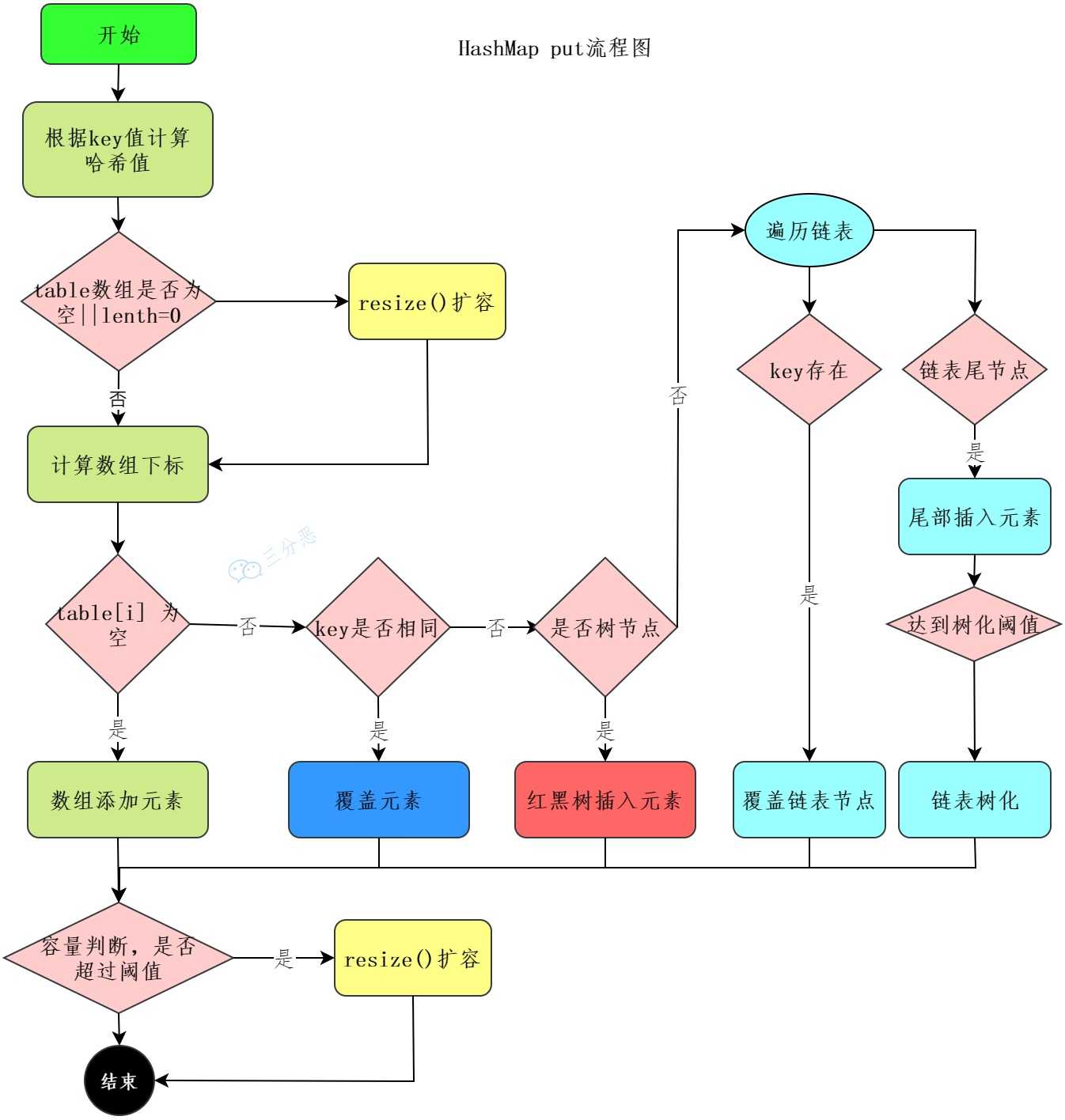
第⼀步,通过 hash ⽅法进⼀步扰动哈希值,以减少哈希冲突。
第⼆步,进⾏第⼀次的数组扩容;并使⽤哈希值和数组⻓度进⾏取模运算,确定索引位置。
如果当前位置为空,直接将键值对插⼊该位置;否则判断当前位置的第⼀个节点是否与新节点的 key 相同,如果相同直接覆盖 value,如果不同,说明发⽣哈希冲突。
如果是链表,将新节点添加到链表的尾部;如果链表⻓度⼤于等于 8,则将链表转换为红⿊树
每次插⼊新元素后,检查是否需要扩容,如果当前元素个数⼤于阈值,则进⾏扩容,扩容后的数组⼤⼩是原来的 2 倍;并且重新计算每个节点的索引,进⾏数据重新分布